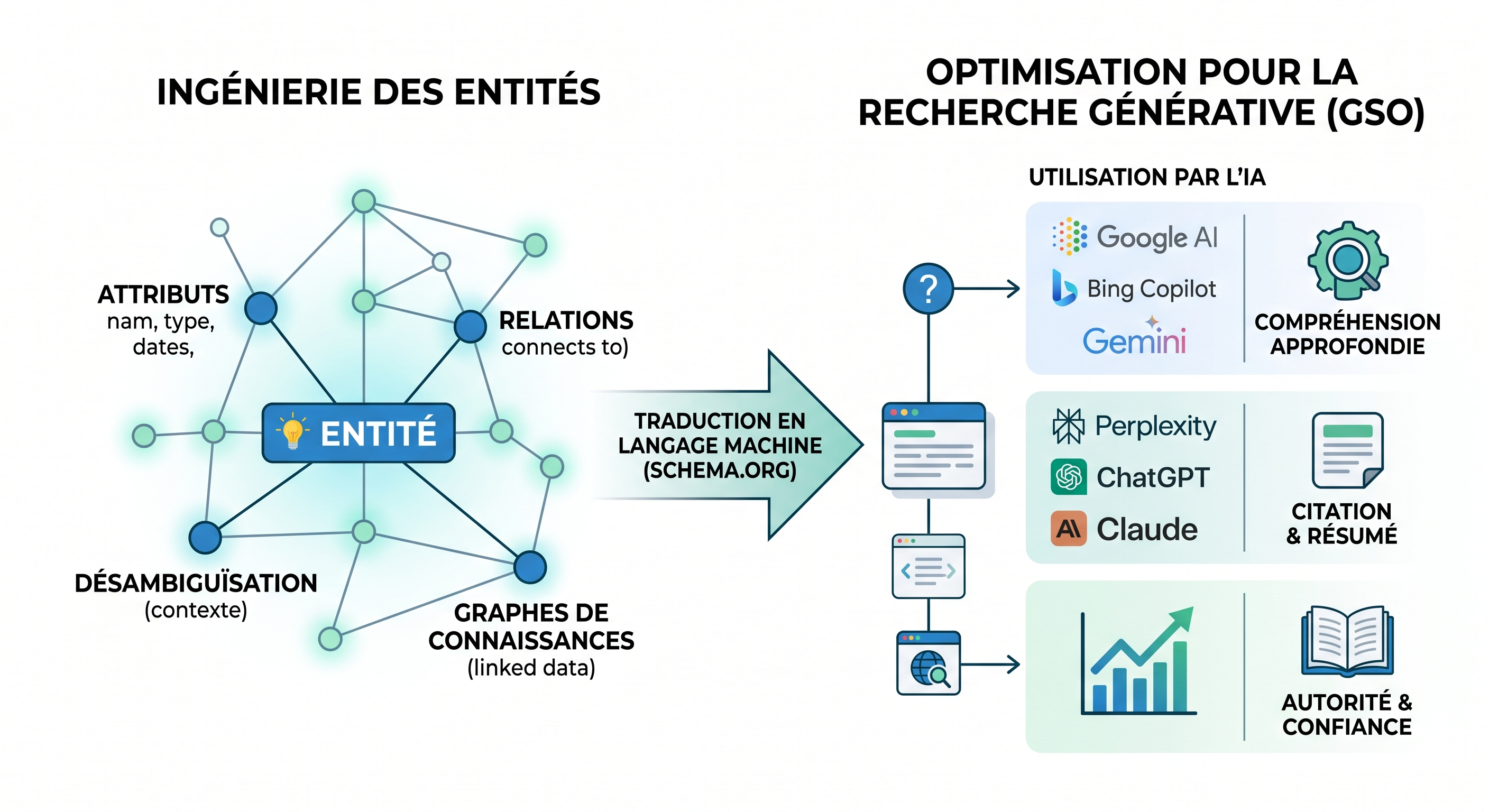
Une discipline naît quand des chercheurs lui donnent un nom, des méthodes et des métriques. Pour l'ingénierie des entités, ces trois éléments sont désormais réunis.
L'ingénierie des entités est la discipline qui prépare l'identité algorithmique d'une marque pour qu'elle soit citée par les moteurs IA Google AI Overviews, ChatGPT, Perplexity, Gemini, Claude. Dix publications scientifiques publiées entre novembre 2023 et mars 2026 par Princeton, Georgia Tech, UC Berkeley, l'Université de Toronto, Columbia, MIT Sloan et l'Allen Institute for AI fondent les méthodes mesurables de cette discipline.
Ce que je vous propose dans cet article n'est pas un avis. C'est une cartographie. Pendant six mois, j'ai lu, annoté, croisé et synthétisé les dix publications les plus structurantes de ce qu'on appelle désormais dans la littérature anglophone Generative Engine Optimization, et que je traduis en français par ingénierie des entités. Ces dix papiers définissent les chiffres, les frameworks, les biais et les méthodes qui pilotent la visibilité algorithmique des marques en 2026.
Trois conclusions ressortent de cette synthèse. La première : la discipline n'est plus émergente, elle est mesurable. La deuxième : les marques qui ignorent ces fondements scientifiques piloteront leur visibilité à l'aveugle pour les trois années à venir. La troisième : aucun acteur français du conseil marketing ne s'appuie aujourd'hui sur cette littérature. C'est la fenêtre d'attaque.
Pourquoi cette synthèse maintenant
Trois chiffres expliquent l'urgence. Selon SparkToro et SemRush, 60 % des recherches Google ne génèrent plus aucun clic vers un site web, les utilisateurs trouvent leur réponse directement dans la page de résultats. Les études de marché 2024-2025 montrent que la position 1 sur Google perd 58 % de son taux de clic quand un AI Overview est affiché au-dessus. Et Google a confirmé à I/O 2026 que 75 % des recherches affichent désormais un résumé IA.
Les implications pour les marques sont structurelles. Optimiser une page pour Google au sens 2015-2020 du terme title tag, méta description, mots-clés, backlinks produit aujourd'hui une fraction du trafic qu'elle produisait il y a cinq ans. Le terrain de la visibilité s'est déplacé : il ne s'agit plus d'apparaître dans une liste de dix résultats, il s'agit d'être cité dans la réponse synthétique que produisent ChatGPT, Perplexity, Gemini ou Claude.
Cette mutation appelle une discipline nouvelle, avec son propre corpus scientifique. Ce corpus existe désormais. Le voici, papier après papier.
Le papier fondateur : GEO (KDD 2024)
Le papier qui ouvre la discipline porte le nom GEO, pour Generative Engine Optimization. Publié sur arXiv en novembre 2023 sous la référence 2311.09735, présenté à KDD 2024 la conférence de référence en data mining il est signé Pranjal Aggarwal, Vishvak Murahari, Karthik Narasimhan et Ameet Deshpande de Princeton University, avec Tanmay Rajpurohit de Georgia Institute of Technology et Ashwin Kalyan de l'Allen Institute for AI.
Le papier formalise pour la première fois ce qu'est un moteur génératif comme paradigme distinct du moteur de recherche classique. Il introduit la métrique Position-Adjusted Word Count, qui mesure combien de mots d'un contenu donné se retrouvent dans la réponse générée par un LLM, pondérés par leur position. Il établit le benchmark GEO-bench : 10 000 requêtes réparties sur 25 domaines, validées sur Perplexity.ai. Et surtout, il teste neuf stratégies d'optimisation et en isole quatre qui produisent un gain de visibilité statistiquement significatif.
+41 % Citations sourcées
+32 % Statistiques
+30 % Références
+28 % Fluidité
Ces quatre chiffres doivent être appris par cœur par toute direction marketing en 2026. Ils signifient qu'un contenu qui cite ses sources gagne 41 % de visibilité dans les moteurs IA, qu'un contenu qui contient des statistiques chiffrées gagne 32 %, qu'un contenu qui référence des publications gagne 30 %, et qu'un contenu rédigé avec fluidité phrases bien construites, transitions claires gagne 28 %.
L'ironie n'échappera à personne : les quatre interventions qui maximisent la citation par les LLMs sont aussi celles qu'enseigne le journalisme depuis cent ans. Citer, chiffrer, référencer, rédiger correctement. Ce sont les mêmes leviers appliqués à une mécanique nouvelle.
La structure compte autant que le sens
Le deuxième papier majeur prolonge le premier sur un angle inattendu. Publié en mars 2026 sous la référence 2603.29979 par Y. Yu, MuFeng, X. Ding et K. Sato, il s'intitule Structural Feature Engineering for Generative Engine Optimization et introduit l'acronyme GEO-SFE.
La thèse est radicale : la structure d'un contenu — indépendamment de sa sémantique — décide de sa citation par les moteurs IA. Deux articles avec le même contenu sémantique mais des structures HTML différentes obtiennent des taux de citation différents. La hiérarchie H1/H2/H3, le placement des passages extractibles, la présence de listes structurées, l'usage des données tabulaires : chacun de ces éléments est un signal mesurable.
Ce papier valide scientifiquement ce que les praticiens soupçonnaient depuis 2024 : optimiser le sens d'un contenu sans optimiser sa structure produit la moitié du résultat. C'est l'ouverture d'un quatrième pilier méthodologique la machine-readability, ou lisibilité par agent distinct de l'optimisation sémantique classique.
Pour les marques, l'implication est concrète : un audit qui n'évalue que la pertinence du contenu, sans évaluer la structure HTML et les schémas de données, manque la moitié du levier.
L'intention comme méta-signal
Le troisième papier déplace le curseur du contenu vers l'intention de recherche. Référencé 2508.11158, signé Chen et al. en août 2025 puis révisé en mars 2026, il s'intitule Role-Augmented Intent-Driven GEO.
Sa contribution principale est G-Eval 2.0, une grille d'évaluation à six niveaux augmentée par LLM. Là où les méthodologies précédentes notaient un contenu sur une échelle binaire bon ou mauvais pour la citation — G-Eval 2.0 introduit une granularité fine qui s'aligne sur le jugement humain. Six niveaux qui décrivent six étapes du parcours intentionnel d'un utilisateur, de la simple curiosité à la décision d'achat.
L'apport opérationnel est direct : un contenu calibré sur un seul niveau d'intention par exemple la phase de découverte sera moins cité qu'un contenu qui couvre explicitement plusieurs niveaux. C'est pourquoi un article qui veut émerger doit traiter à la fois la définition d'un concept, ses applications, ses limites et ses alternatives. Pas par volonté de longueur, mais par construction intentionnelle.
G-Eval 2.0 est en train de devenir le barème de référence pour les audits de citabilité par les agences spécialisées. Watizi l'a intégré dans le Diagnostic IA, où les sept axes scorés sur 100 points reprennent la logique de gradation intentionnelle.
Le biais earned media — University of Toronto
Le quatrième papier est probablement le plus dérangeant de la liste pour les directions marketing. Publié en septembre 2025 par l'équipe de Chen à l'Université de Toronto sous la référence 2509.08919, il établit par expérimentation contrôlée à grande échelle un fait que personne ne contestait intuitivement mais qui n'avait jamais été mesuré scientifiquement.
Les moteurs IA ChatGPT, Perplexity, Gemini favorisent systématiquement et massivement les sources tierces autoritatives (earned media : presse, sites institutionnels, publications spécialisées) au détriment du contenu propriétaire des marques et du contenu social. Et ce biais résiste à la paraphrase des requêtes : ce n'est pas un artefact de formulation, c'est une préférence structurelle des moteurs.
« Recherche IA présente un biais systématique et massif en faveur du earned media, en contraste frappant avec la composition plus équilibrée des citations Google. » Chen et al., University of Toronto, arXiv:2509.08919, septembre 2025
L'implication budgétaire est immédiate. Une marque qui investit l'essentiel de son budget visibilité dans le contenu de son site et dans la publicité sociale construit une présence que les moteurs IA déprécient structurellement. Les budgets historiquement alloués au SEO on-page doivent migrer en partie vers des actions earned media : relations presse, partenariats éditoriaux, présence dans des publications spécialisées, articles invités sur des médias autoritatifs.
Ce papier explique aussi un phénomène que je vois sur le terrain depuis dix-huit mois : des marques avec un excellent SEO et un excellent contenu de marque restent absentes des AI Overviews et des réponses ChatGPT, quand des marques moins bien optimisées techniquement mais davantage présentes dans la presse spécialisée émergent immédiatement. Le biais earned media est cette explication.
Le repositionnement budgétaire que cela implique n'est pas trivial. Il demande de réinventer les relations entre direction marketing, direction de la communication et relations presse — trois fonctions historiquement cloisonnées qui doivent désormais piloter ensemble la part de voix algorithmique de la marque.
Le cadre de mesure : GEO-16 (UC Berkeley)
Si l'étude de Toronto pose le diagnostic, le cinquième papier propose la méthode. Publié également en septembre 2025 par Kumar et al. à l'Université de Californie à Berkeley sous la référence 2509.10762, GEO-16 est le premier framework d'audit complet et reproductible d'une page web pour sa citabilité par les moteurs IA.
La méthodologie est rigoureuse : 1 702 citations analysées sur Brave Search, Google AI Overviews et Perplexity, couvrant 70 prompts répartis sur 16 verticales B2B SaaS. Le framework évalue chaque page sur seize piliers structurels regroupés en trois familles.
Famille | Piliers évalués | Nombre |
|---|---|---|
Métadonnées et fraîcheur | Title tag, meta description, dates de publication et modification, balises canoniques | 4 |
Sémantique HTML | Hiérarchie H1/H2/H3, balises sémantiques HTML5, ancres internes descriptives, attributs alt, structure de paragraphes | 5 |
Données structurées | JSON-LD Article, FAQPage, BreadcrumbList, Organization, Person, sameAs cohérents, identifiants externes (Wikidata, ORCID) | 7 |
Chaque pilier est noté sur une échelle continue. Le score composite G de la page est la moyenne pondérée des seize piliers. Et c'est là que se trouve le résultat le plus exploitable de l'étude : les pages atteignant un score G supérieur à 0,70 avec au moins douze piliers validés obtiennent un taux de citation cross-engine de 78 %. Le rapport de cote de citation pour ces pages est de 4,2 autrement dit, une page de score élevé a 4,2 fois plus de chances d'être citée qu'une page de score moyen.
Pour Watizi, ce framework est devenu une référence centrale. Le Diagnostic IA gratuit que nous délivrons à nos prospects mappe ses sept axes sur les seize piliers GEO-16. Notre scoring sur 100 points est calibré pour qu'un score Diagnostic IA supérieur à 70 corresponde à un score G Berkeley supérieur à 0,70 donc à un taux de citation cross-engine attendu de 78 %.
L'usage opérationnel pour une marque tient en une question : combien de mes seize piliers sont validés à ce jour ? Si la réponse est huit ou moins, la marque est invisible dans les moteurs IA et il faut intervenir en priorité.
L'économie des agents : trois publications convergentes
Trois publications publiées entre avril et novembre 2025 décrivent une mutation parallèle aux moteurs de recherche : la montée des agents IA capables de naviguer, lire, comparer et acheter pour le compte d'un utilisateur. Cette mutation déplace la cible de l'optimisation : la lecture du contenu d'une marque ne se fait plus seulement par un humain qui scrolle, mais par un agent autonome qui parse.
ACES — l'audit des choix d'agent (Columbia / Yale)
Le premier de ces trois papiers s'intitule What Is Your AI Agent Buying ? et introduit le cadre d'audit ACES. Publié en août 2025 sous la référence 2508.02630 par des chercheurs de la Columbia Business School et de Yale, il propose un cadre fournisseur-agnostique pour auditer les décisions d'agents en e-commerce.
Deux résultats sont structurants. D'abord, les agents IA concentrent la demande sur quelques produits modaux : dans les tests menés avec ACES, les choix se concentrent sur quelques produits « modaux » tandis que d'autres ne sont jamais sélectionnés. Surtout, les parts de marché varient fortement selon le modèle — un même produit peut être choisi 45 % du temps par un modèle et environ 25 % par un autre. Ensuite, les préférences des agents sont instables : une mise à jour de modèle peut redistribuer les parts de marché du jour au lendemain, sans intervention humaine.
Pour les directions e-commerce, l'implication est lourde. Un budget Google Ads de plusieurs dizaines de milliers d'euros par mois peut perdre soudainement sa pertinence si une part significative de l'audience cible bascule vers un agent IA qui sélectionne d'autres produits. La machine-readability des fiches produit — JSON-LD Product complet, Schema Offer rigoureux, métadonnées prix et stock à jour — devient un avantage concurrentiel direct sur les compétiteurs qui n'auront pas anticipé.
Building Browser Agents — la nouvelle interface
Le deuxième papier, référencé 2511.19477 et publié en novembre 2025, cartographie l'écosystème des navigateurs IA. ChatGPT Atlas, lancé par OpenAI en octobre 2025, intègre un Agent Mode capable d'exécuter des tâches autonomes — planification de voyage, achats — sur les onglets de l'utilisateur. Perplexity Comet, annoncé en juillet 2025, fonctionne comme une IA dans le navigateur. Manus AI, plus récent, propose une approche similaire.
Le papier soulève un point critique : les standards web actuels (cookies, consentement, contrôle des autorisations) ne suffisent plus à arbitrer la lecture du contenu par un agent. Une page peut être lue, interprétée et résumée par un agent sans que le propriétaire du site en soit informé. Cela change le cadre juridique et économique de la publication web.
AI Agents face à la publicité en ligne
Le troisième papier, 2504.07112, publié en avril 2025, étudie le comportement des agents face aux formats publicitaires. L'étude est sectorielle appliquée au voyage mais ses conclusions sont généralisables. Les agents IA traitent la publicité différemment selon le modèle multimodal sous-jacent (GPT-4o, Gemini, Claude) et selon le format publicitaire. Surtout, l'étude projette que les moteurs classiques perdront jusqu'à 25 % de leurs requêtes d'ici fin 2026 au profit des assistants IA.
L'enchaînement de ces trois publications dessine une équation simple : le canal d'acquisition Google Ads, qui représente encore l'essentiel des budgets digitaux en 2026, perd progressivement son public. Ce public ne disparaît pas il bascule vers des agents qui lisent autrement, sélectionnent autrement, achètent autrement. Préparer son site à cette transition n'est plus optionnel.
E-GEO : la déclinaison e-commerce
La huitième publication de cette synthèse, référencée 2511.20867, publiée en novembre 2025 par les départements d'ingénierie industrielle de Columbia et MIT Sloan, applique le cadre GEO au contexte e-commerce. Elle s'intitule E-GEO et constitue le premier testbed dédié à la visibilité des sites marchands dans les moteurs génératifs.
Le constat opérationnel est le suivant : les moteurs génératifs agissent en e-commerce en surfaçant et en ordonnant les produits existants selon l'intention inférée de l'utilisateur. Le benchmark E-GEO — plus de 7 000 requêtes consommateurs associées à des fiches produits — évalue quinze heuristiques de réécriture et met en évidence un motif d'optimisation stable, indépendant du domaine. Les signaux qui pèsent sont substantiellement différents des signaux SEO classiques : la richesse des données structurées, la cohérence du JSON-LD Product, la précision des attributs (taille, matière, origine, stock), la vivacité des reviews, et l'autorité des sources externes citant le produit.
Pour une marque e-commerce qui veut émerger dans le commerce agentique — ce mode d'achat où l'agent IA décide à la place de l'utilisateur — la conformité E-GEO devient une priorité de roadmap technique. Plus que la refonte d'un site, c'est la rigueur des fiches produit qui se joue.
Le monitoring longitudinal des citations
La dixième et dernière publication structurante referme le corpus en posant les fondations méthodologiques du suivi mensuel des citations. Publiée en juillet 2025 sous la référence 2507.05301 et intitulée News Source Citing Patterns in AI Search Systems, elle décrit comment les moteurs IA citent les sources d'information sur la durée.
Trois enseignements pratiques : les patterns de citation évoluent significativement d'une semaine à l'autre, ce qui rend nécessaire un monitoring continu et non ponctuel. Les sources émergentes peuvent être adoptées rapidement par les moteurs si elles produisent du contenu de qualité avec les bons signaux structurels. Et inversement, des sources historiquement citées peuvent disparaître en quelques semaines si leur fraîcheur baisse.
C'est cette publication qui légitime scientifiquement le passage du Brand Citation Monitoring — métrique ponctuelle — à la Continuous Agent Surveillance — métrique longitudinale. Watizi a renommé son service de monitoring dans cette logique en juin 2026.
Synthèse : la discipline en 2026
Les dix publications synthétisées dans cet article ne forment pas une collection hétéroclite. Elles dessinent ensemble une discipline cohérente, avec ses fondements, ses méthodes et ses métriques. Le tableau ci-dessous récapitule les apports.
Publication | Institution | Date | Apport principal |
|---|---|---|---|
Princeton, Georgia Tech, AI2 | Nov. 2023 | Papier fondateur GEO. Métrique PAWC. Les 4 chiffres clés (+41/+32/+30/+28 %) | |
Yu, MuFeng, Ding, Sato | Mars 2026 | GEO-SFE. La structure compte autant que le sens. | |
Chen et al. | Août 2025 | G-Eval 2.0. Scoring à 6 niveaux d'intention. | |
University of Toronto | Sept. 2025 | Biais earned media massif des moteurs IA. | |
UC Berkeley | Sept. 2025 | Framework GEO-16. Score G ≥ 0,70 → 78 % de citation cross-engine. | |
Columbia, Yale | Août 2025 | ACES. Audit des choix d'agent — concentration sur des produits modaux, parts de marché instables selon le modèle. | |
Recherche multi-institutions | Nov. 2025 | Architecture des browser agents. Atlas, Comet, Manus. | |
Étude sectorielle voyage | Avr. 2025 | -25 % de requêtes Google d'ici fin 2026 au profit des assistants IA. | |
Columbia, MIT Sloan | Nov. 2025 | E-GEO. Application au e-commerce. Benchmark e-commerce (7 000+ requêtes, 15 heuristiques), motif d'optimisation universel. | |
Étude longitudinale | Juil. 2025 | News Citing Patterns. Méthodologie du monitoring longitudinal. |
Quatre piliers méthodologiques émergent de cette synthèse, qui structurent désormais une stratégie de visibilité algorithmique professionnelle :
Pilier 1 — Transformation IA. Ancrer l'identité de la marque dans le Knowledge Graph (Wikidata, schema.org, llms.txt) pour qu'elle soit reconnaissable par les moteurs.
Pilier 2 — Marketing augmenté (GEO/AEO). Produire des contenus qui appliquent les quatre interventions chiffrées par le papier Princeton (citations, statistiques, références, fluidité).
Pilier 3 — Continuous Agent Surveillance. Mesurer en continu la part de voix de la marque dans les moteurs IA et ajuster.
Pilier 4 — Multimodal Entity Layer. Préparer la machine-readability du site pour les agents acheteurs (JSON-LD multimodal, transcripts, alt-text orientés entités, OCR-readiness).
Aucun de ces piliers n'existait formellement il y a trois ans. Tous les quatre sont aujourd'hui mesurables, documentés et appliqués par les marques les plus avancées.
Le travail des trois prochaines années consistera à transposer ces fondements scientifiques en pratiques opérationnelles standardisées. C'est ce que Watizi fait, papier après papier, prospect après prospect. Si vous voulez savoir où votre marque se situe par rapport à ces fondements, le Diagnostic IA gratuit est conçu pour répondre à cette question en 90 minutes.
Philippe Trento
Références scientifiques
Aggarwal P., Murahari V., Rajpurohit T., Kalyan A., Narasimhan K., Deshpande A. (2024). GEO: Generative Engine Optimization. KDD 2024. arXiv:2311.09735
Yu Y., MuFeng, Ding X., Sato K. (2026). Structural Feature Engineering for Generative Engine Optimization: How Content Structure Shapes Citation Behavior. arXiv:2603.29979
Chen et al. (2025). Role-Augmented Intent-Driven Generative Search Engine Optimization. arXiv:2508.11158
Chen M., Wang X., Chen K., Koudas N., University of Toronto (2025). Generative Engine Optimization: How to Dominate AI Search. arXiv:2509.08919
Kumar A., Palkhouski L., UC Berkeley (2025). AI Answer Engine Citation Behavior: An Empirical Analysis of the GEO-16 Framework. arXiv:2509.10762
Allouah A., Besbes O., Figueroa J., Kanoria Y., Kumar A. (2025). What Is Your AI Agent Buying? Evaluation, Biases, Model Dependence, & Emerging Implications for Agentic E-Commerce (cadre ACES). Columbia Business School, Yale. arXiv:2508.02630
Multi-institutional (2025). Building Browser Agents: Architecture, Security, and Practical Solutions. arXiv:2511.19477
Sectoral study (2025). Are AI Agents Interacting with Online Ads?. arXiv:2504.07112
Columbia Industrial Engineering, MIT Sloan (2025). E-GEO: A Testbed for Generative Engine Optimization in E-Commerce. arXiv:2511.20867
Longitudinal study (2025). News Source Citing Patterns in AI Search Systems. arXiv:2507.05301
Évaluez la maturité algorithmique de votre marque
Le Diagnostic IA Watizi reprend les seize piliers du framework GEO-16 et les sept axes méthodologiques issus de la littérature scientifique synthétisée dans cet article. Restitution en 90 minutes, rapport PDF de 6 pages.